Gagan Khandategagank at cs dot columbia dot edu Hi, I'm Gagan! I'm a Staff Research Scientist at Boston Dynamics, where I work on dexterous intelligence for the Atlas humanoid with the goal of bridging the gap between robotic and human-level dexterity in the real world. I earned my Ph.D. in Computer Science from Columbia University, where I was fortunate to advised by Matei Ciocarlie. My research focuses on enabling robots with multi-fingered hands to perform complex, human-like manipulation with sense of touch. To that end, I develop reinforcement learning algorithms guided by structured exploration, often combining sampling-based planning with learning to efficiently navigate high-dimensional action spaces. I'm particularly interested in scaling dexterous capabilities by learning from instrumented human demonstrations—leveraging rich, multimodal data to acquire intricate manipulation skills that are difficult to hard-code. Ultimately, I aim to build systems that can adaptively learn to manipulate like humans in the messiness of the real world. During my Ph.D, I had the amazing opportunities work at various industry research labs - Applied Scientist Intern at Amazon Robotics AI (RAI), Boston in Summer 2022, Research Scientist Intern at Meta Reality Labs (CTRL Labs), New York.I enjoy discussing research ideas, learning from others, and occasionally scheming about what’s next in robotics and intelligent systems. If you're exploring related problems—or just like thinking about robots that can actually use their hands—feel free to reach out. |

|
News
|
Pre-prints
|
|
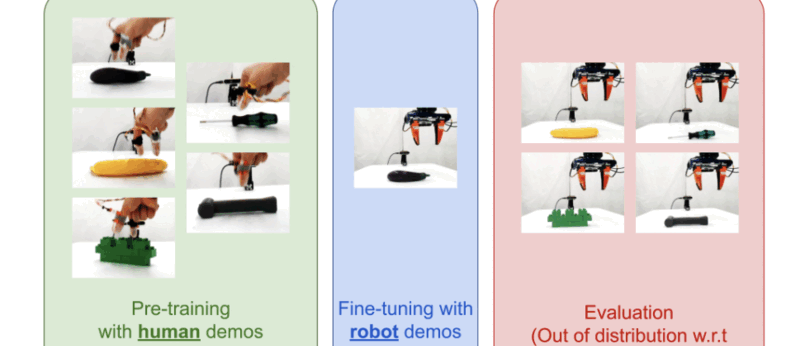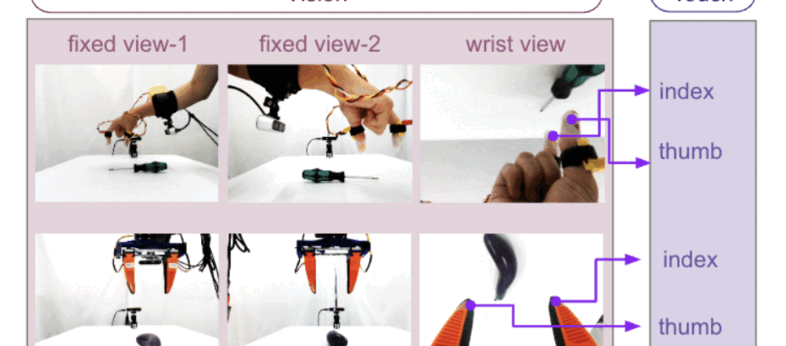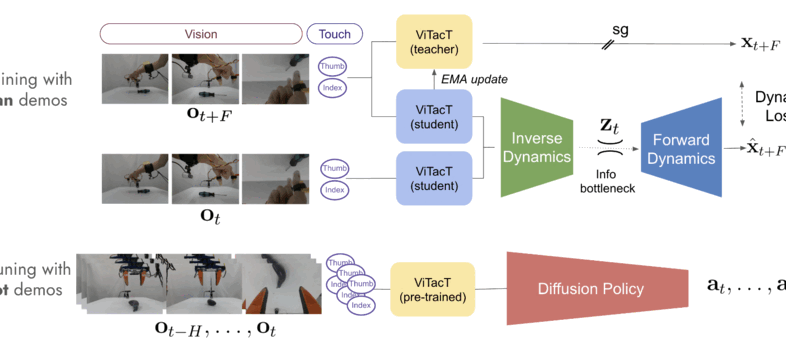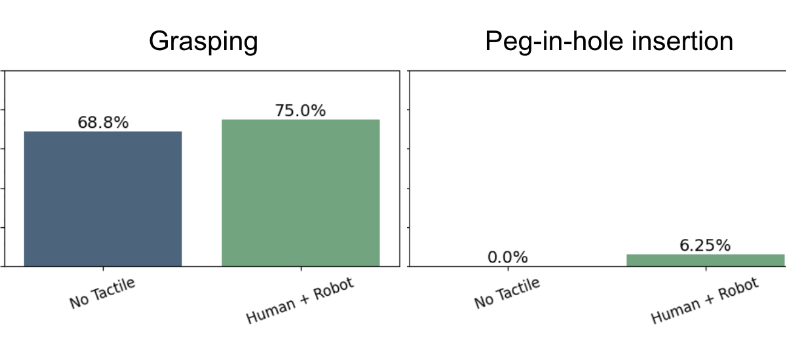
Train Robots in a JIF: Joint Inverse and Forward Dynamics with Human and Robot DemonstrationsGagan Khandate*, Boxuan Wang*, Sarah Park*, Weizhe Ni, Joaquin Palacios, Kathyrn Lampo, Philippe Wu, Rosh Ho, Eric Chang, Matei Ciocarlie Submitted to RSS 2025, 2025 arxiv / Pre-training on large datasets of robot demonstrations is a powerful technique for learning diverse manipulation skills but is often limited by the high cost and complexity of collecting robot-centric data, especially for tasks requiring tactile feedback. This work addresses these challenges by introducing a novel method for pre-training with multi-modal human demonstrations. Our approach jointly learns inverse and forward dynamics to extract latent state representations, towards learning manipulation specific representations. This enables efficient fine-tuning with only a small number of robot demonstrations, significantly improving data efficiency. Furthermore, our method allows for the use of multi-modal data, such as combination of vision and touch for manipulation. By leveraging latent dynamics modeling and tactile sensing, this approach paves the way for scalable robot manipulation learning based on human demonstrations. |
Publications
|
|
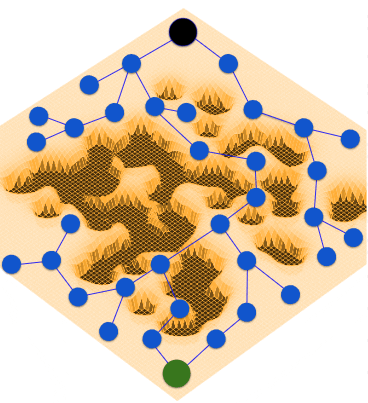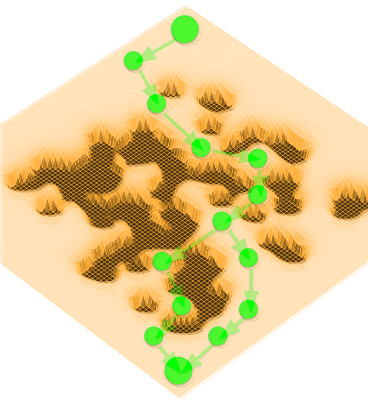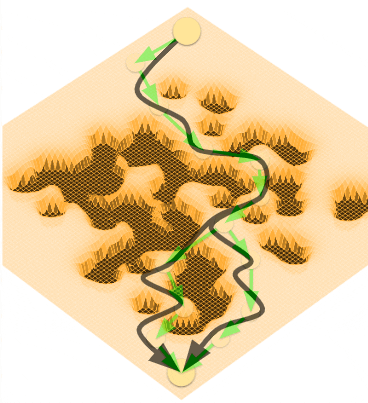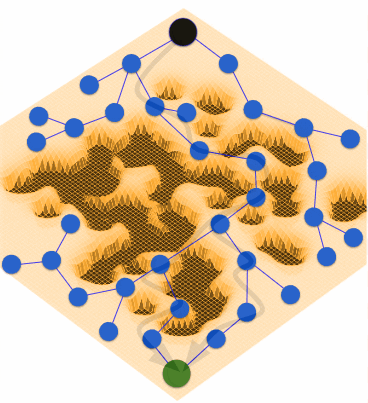
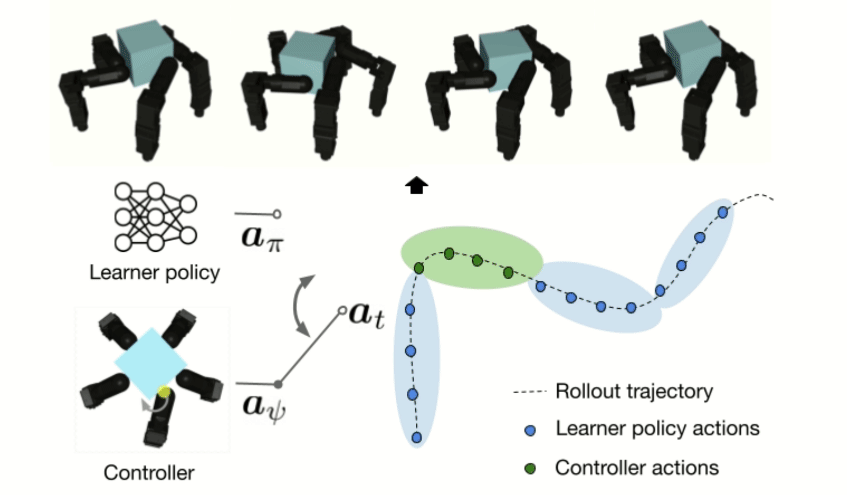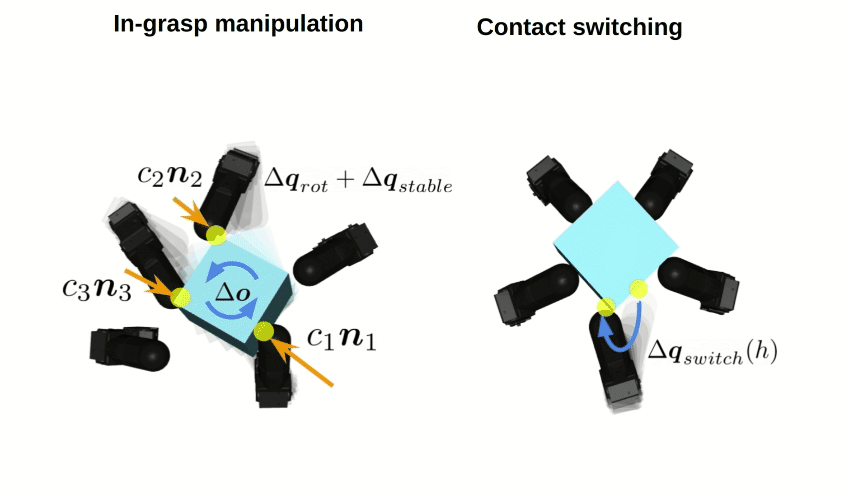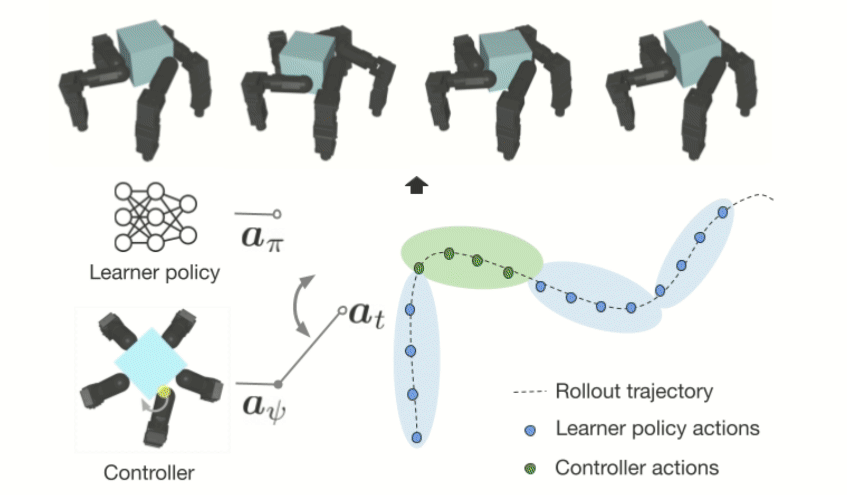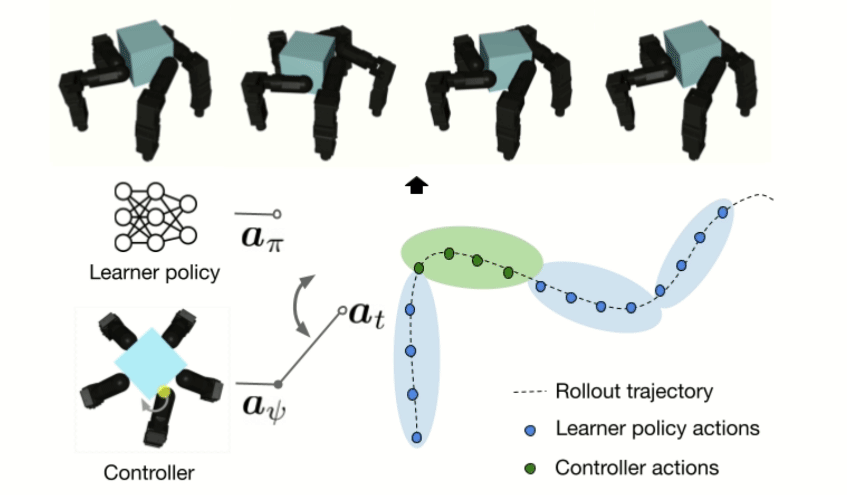
RxR: Rapid eXploration for Reinforcement Learning via Sampling-based Reset Distributions and Imitation Pre-trainingGagan Khandate*, Tristan Luca Saidi*, Siqi Shang*, Eric Chang, Johnson Adams, Matei Ciocarlie Autonomous Robots - RSS 2023 Special Issue, 2024 arxiv / website / We present a method for enabling Reinforcement Learning of motor control policies for complex skills such as dexterous manipulation. We posit that a key difficulty for training such policies is the difficulty of exploring the problem state space, as the accessible and useful regions of this space form a complex structure along manifolds of the original high-dimensional state space. This work presents a method to enable and support exploration with Sampling-based Planning. We use a generally applicable non-holonomic Rapidly-exploring Random Trees algorithm and present multiple methods to use the resulting structure to bootstrap model-free Reinforcement Learning. Our method is effective at learning various challenging dexterous motor control skills of higher difficulty than previously shown. In particular, we achieve dexterous in-hand manipulation of complex objects while simultaneously securing the object without the use of passive support surfaces. These policies also transfer effectively to real robots. A number of example videos can also be found on the project website: https://sbrl.cs.columbia.edu |
|
Value Guided Exploration with Sub-optimal Controllers for Learning Dexterous ManipulationGagan Khandate*, Cameron Mehlman*, Xingsheng Wei*, Matei Ciocarlie International Conference on Intelligent Robots and Systems 2024, 2023 arxiv / website / Recently, reinforcement learning has allowed dexterous manipulation skills with increasing complexity. Nonetheless, learning these skills in simulation still exhibits poor sample-efficiency which stems from the fact these skills are learned from scratch without the benefit of any domain expertise. In this work, we aim to improve the sample-efficiency of learning dexterous in-hand manipulation skills using sub-optimal controllers available via domain knowledge. Our framework optimally queries the sub-optimal controllers and guides exploration toward state-space relevant to the task thereby demonstrating improved sample complexity. We show that our framework allows learning from highly sub-optimal controllers and we are the first to demonstrate learning hard-to-explore finger-gaiting in-hand manipulation skills without the use of an exploratory reset distribution. |

|
Sampling-based Exploration for Reinforcement Learning of Dexterous ManipulationGagan Khandate*, Siqi Shang*, Eric Chang, Tristan Luca Saidi, Johnson Adams, Matei Ciocarlie Robotics: Science & Systems, RSS, 2023 arxiv / website / In this paper, we present a novel method for achieving dexterous manipulation of complex objects, while simultaneously securing the object without the use of passive support surfaces. We posit that a key difficulty for training such policies in a Reinforcement Learning framework is the difficulty of exploring the problem state space, as the accessible regions of this space form a complex structure along manifolds of a high-dimensional space. To address this challenge, we use two versions of the non-holonomic Rapidly-Exploring Random Trees algorithm; one version is more general, but requires explicit use of the environment’s transition function, while the second version uses manipulation-specific kinematic constraints to attain better sample efficiency. In both cases, we use states found via sampling-based exploration to generate reset distributions that enable training control policies under full dynamic constraints via model-free Reinforcement Learning. We show that these policies are effective at manipulation problems of higher difficulty than previously shown, and also transfer effectively to real robots. |

|
On Feasibility of Learning Finger-gaiting In-hand Manipulation using Intrinsic SensingGagan Khandate, Maximillian Haas-Heger, Matei Ciocarlie IEEE International Conference on Robotics and Automation (ICRA), 2022 arxiv / video / website / In this work, we use model-free reinforcement learning (RL) to learn finger-gaiting only via precision grasps and demonstrate finger-gaiting for rotation about an axis purely using on-board proprioceptive and tactile feedback. To tackle the inherent instability of precision grasping, we propose the use of initial state distributions that enable effective exploration of the state space. |

|
Algorithmic Gait Synthesis for a Snake RobotGagan Khandate, Emily Hannigan, Maximilian Haas-Heger, Bing Song, Ji Yin, Matei Ciocarlie Toward Online Optimal Control of Dynamic Robots: From Algorithmic Advances to Field Applications Workshop, ICRA, 2019 arxiv / In this work, we study the use of deep reinforcement learning for control of snake robots. While prior work on control of snake robots primarily uses open loop control backed by sinusoidal gaits (serpenoid curves), we demonstrate the use of deep reinforcement learning (PPO) for generating snake gaits under different environments. We also compare our method with other classes - model predictive control (MPC) and sampling based planning (SPB). Our results show that the gaits generated by model-free deep reinforcement learning are comparable (sometimes better) to MPC in terms of efficiency and energy comsumption. |